深度神經網路(DNN)以其線性和非線性的複雜轉換而聞名,因為它涵蓋了許多隱藏層。因此即使給定一個訓練有素並能夠良好分類的 DNN,模型內部的推論過程仍然是個未知,這使得 DNN 也被稱為黑盒模型。從今天開始我們將進入深度學習的世界,接下來的內容當中會講解一些熱門的神經網路背後是如何被解釋的。
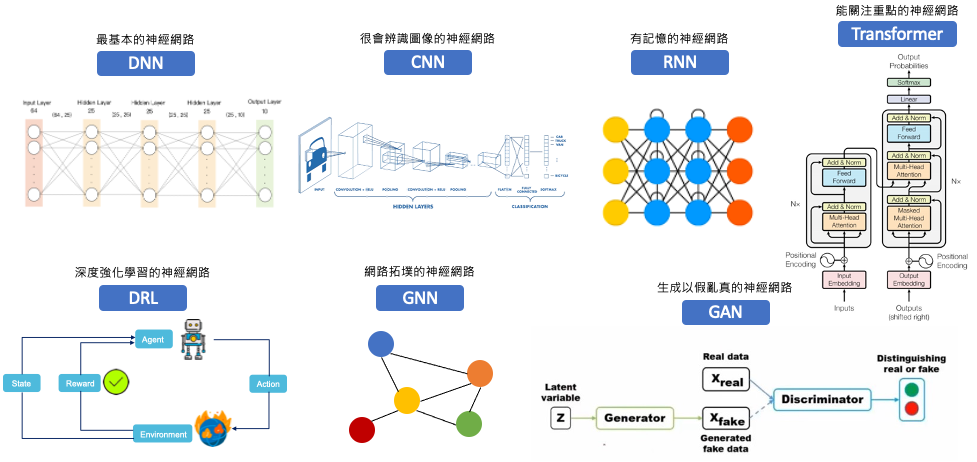
我們可以運用多種方法來解釋深度神經網路的運作,這些方法能夠幫助我們更深入地理解神經網路的運行方式,並解釋模型進行推論的過程。透過從以下幾個角度出發,使我們能夠更深入地探索黑箱模型的內部:
我們可以從特徵貢獻性評估每個輸入特徵對預測的重要程度,其中先前所介紹的可解釋工具 LIME 和 SHAP 也能拿來解釋各種類型的神經網路,例如: DNN、CNN、RNN、LSTM、GRU 等。
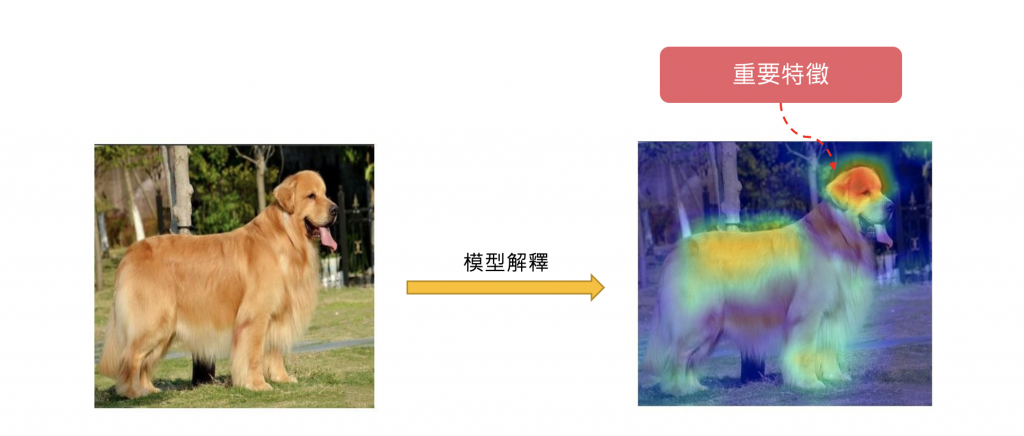
我們可以將神經網路的輸出結果視覺化,並觀察神經網路在推論過程中,哪些特徵影響最大。此概念最常被應用在卷積神經網路(CNN)上,因為 CNN 通常會產生許多特徵圖,我們可以將這些特徵圖視覺化,觀察 CNN 對輸入圖像的解釋。另外近期熱門的大型語言模型都是以 Transformer 為架構搭建出來的神經網路,其中內部核心就是由多個 self-attention 所組成。因此在深度學習中的注意力機制(Self-Attention)也與視覺化結合,我們可以將注意力機制視覺化,觀察模型在推論過程中,哪些特徵影響最大。
對抗性樣本是一種修改後的輸入,可以干擾模型的預測。通過分析模型對對抗性樣本的響應,可以觀察模型的弱點和預測結果的不確定性。
明天開始我們就依序的探索深度神經網路的解釋方法。

